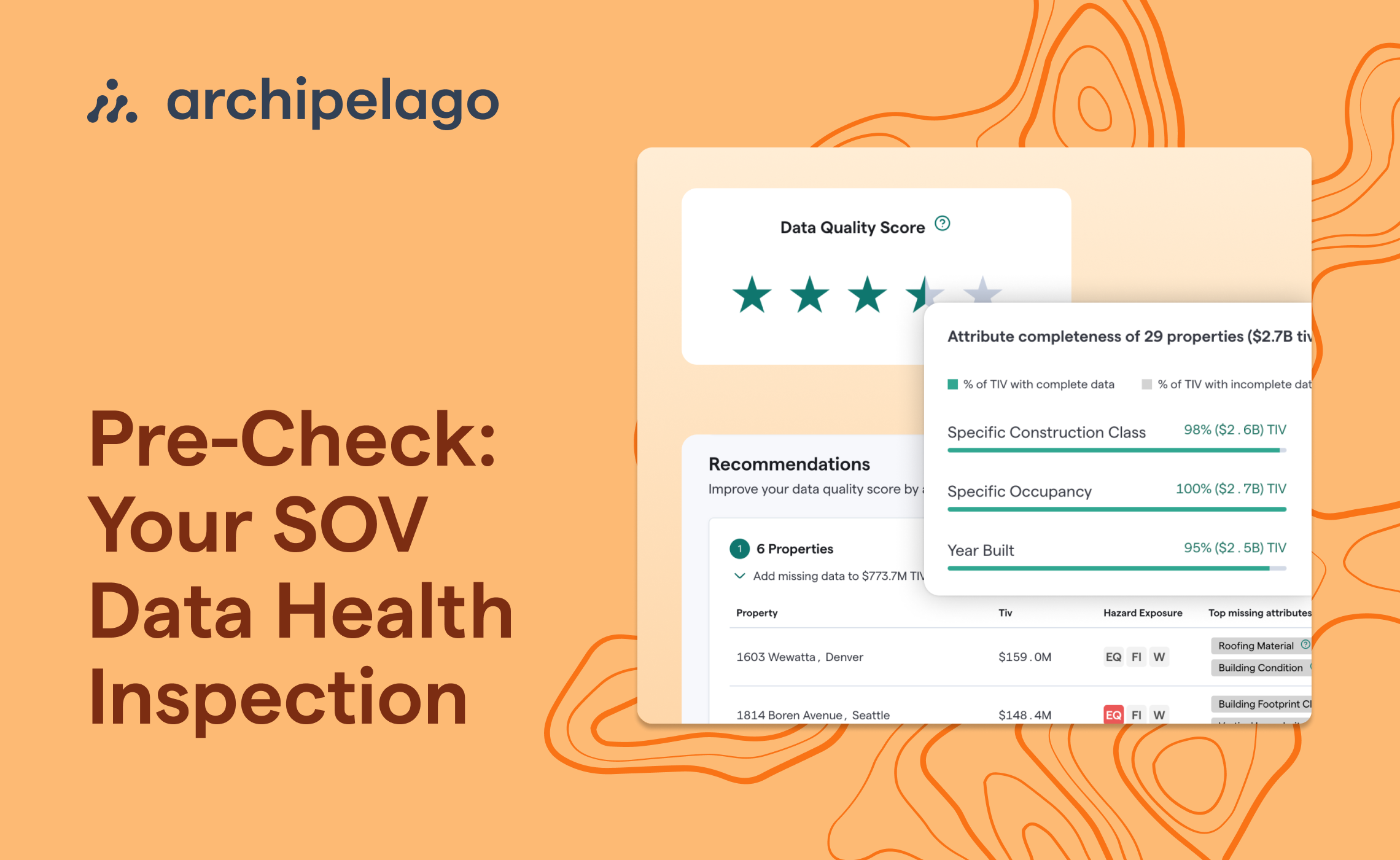
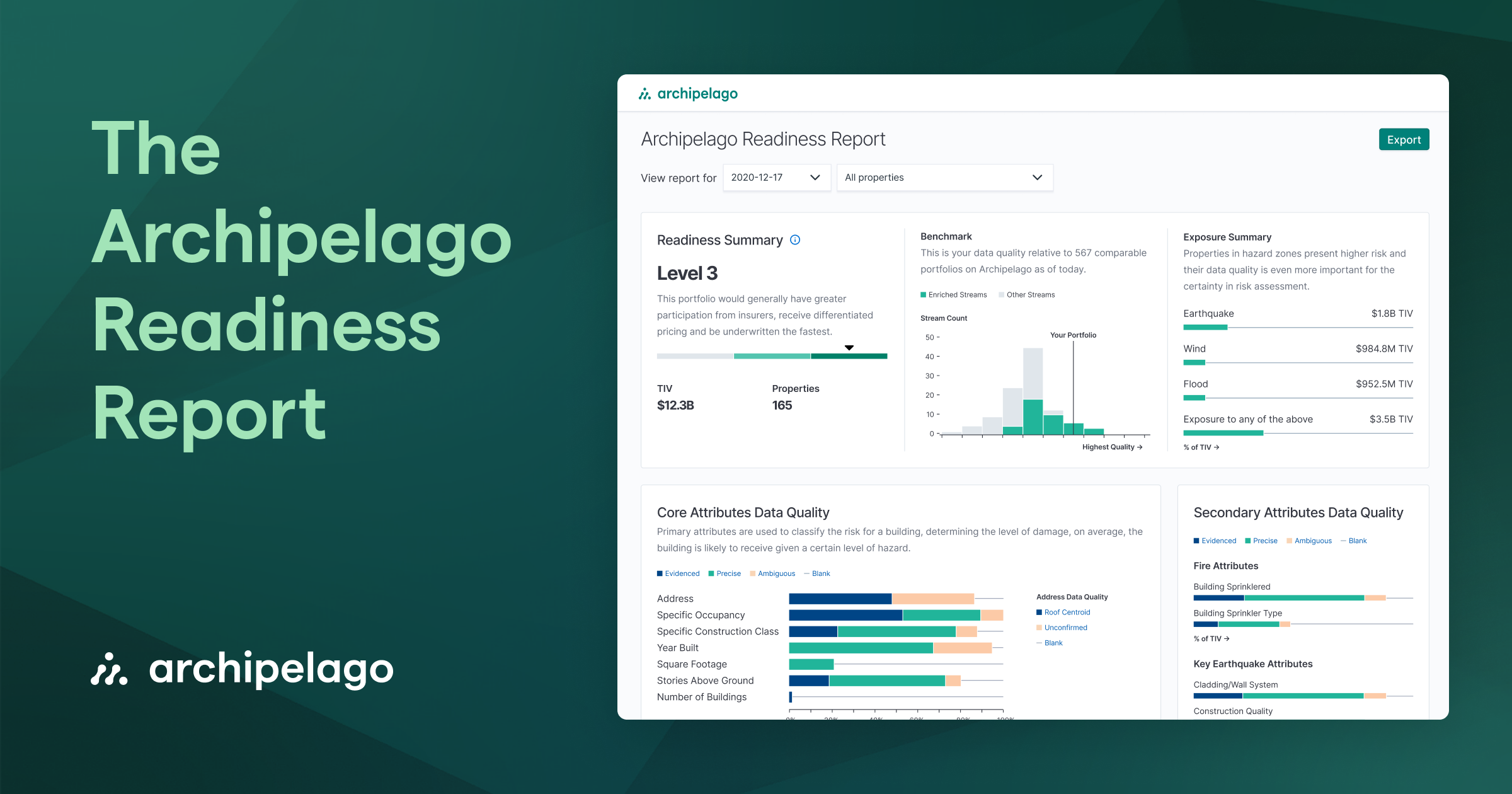
Today, Archipelago meets another milestone as we release integrated loss history data with exposure data on our platform.
Commercial property insurance is a $200B business historically transacted based on incomplete and inaccurate data. It was and in most cases still is maintained on inconsistently formatted spreadsheets and shared amongst multiple stakeholders via email attachments. A single deal may involve numerous brokers and 100+ insurers, each having to manually translate these spreadsheets into usable formats and applying a myriad of assumptions to fill in the gaps.
The truth is that assessing property risk is an extremely labor-intensive process prone to mistakes and simple human error.
When we first started Archipelago in 2018, one of the risk managers we were fortunate enough to partner with stated simply: "there must be a better way."
Since then, we have worked to try to find that better way, beginning with property exposure data by:
- Driving greater completeness and accuracy
- Helping our clients to tap into previously untapped sources of data
- Applying structure to the data to eliminate the need for manual intervention to make it usable
- Allowing this data to be securely accessed by all that need it via a modern digital platform
More recently, our attention has turned to loss data. Our latest release, shaped by engagement with hundreds of risk managers, brokers, and insurers across the market, aims to bring that "better way" to the inconsistent world of losses.
Today, loss data is shared with insurers in the form of loss runs. Like SOVs for exposure data, these loss runs are inconsistently formatted spreadsheets with inconsistent levels of information. For example, some loss runs include details of each loss, and some just aggregate totals for five or more years. Those totals may represent all losses or just those that resulted in claims above the client’s retention. Also, they may be losses on all buildings insured in any particular year or just those on buildings that remain in the current portfolio. Whatever the information provided, each insurer (just as they do with exposure data), has to evaluate and translate what they receive into something usable. This process can take hours, if not days, of effort.
Accurate and comprehensive loss data is both critical and mandatory for the underwriting process.
Underwriters use historical loss data as a key predictor of how a portfolio will perform in the future. Understanding the nature of those losses and whether they are likely to be repeated is fundamental to their decisions regarding whether to offer coverage and if so, how much and at what price.
Equally, many risk managers will be painfully aware that the cost of insuring loss-heavy portfolios has more than doubled over the last three years. For these risk managers, securing adequate coverage at a reasonable price depends on articulating what losses have happened, what has been done to address them, and having the understanding and flexibility to mitigate risk for insurers through coverage terms, such as raising deductibles. Those fortunate enough to have avoided significant losses will equally want to emphasize what has not happened and why the resiliency measures they have taken mean those losses continue to be unlikely.
Integrated loss data with exposure data is a multiplier for getting the best outcome.
Given these priorities, our approach to losses is not dissimilar to how we have tackled exposure data:
- Work with clients to build the level of accuracy, completeness, granularity, and clarity that insurers need. This means ground-up loss data for a target of five years, with details of each and every loss rather than in aggregate, including key data points such as cause of loss and/or name of the event.
- Bring structure to that data through alignment to a consistent and clearly defined schema.
- Integrate that data with a client’s exposures, mapping each loss to the specific property affected.
- Provide a layer of analytical capabilities that support all the key ways in which risk managers, brokers, and insurers seek to slice and dice loss data to understand the loss dynamics of any portfolio.
A better way for risk managers, brokers, and underwriters
With these new capabilities:
- Risk managers can further differentiate their submissions, telling their stories with data-driven evidence and highlighting investments in resiliency or superior risk management practices.
- Brokers are also better equipped to understand key loss drivers and what may be problematic in renewals, prompting proactive approaches to address what are likely to be underwriting concerns through creative insurance program structures.
- Underwriters, some of whom may not have even looked at certain loss-heavy portfolios before, can quickly, easily, and efficiently get a rich understanding of the client’s loss story and how that translates into the frequency and severity of losses going forward.
As always, these are just the first steps in a longer strategic journey. Over time, with the steady accumulation of structured and highly granular loss data, we will be able to offer unprecedented analytic insight into the performance of any client’s property portfolio through capabilities such as loss benchmarking.
For now, we humbly offer these new features, alongside those already delivered and trusted by many of the world’s leading risk managers, as a significant milestone in our ongoing mission to find that "better way."
We'd be happy to show you how your risk profile improves with Archipelago’s integrated losses and exposures. Get a personalized demo of our platform now.