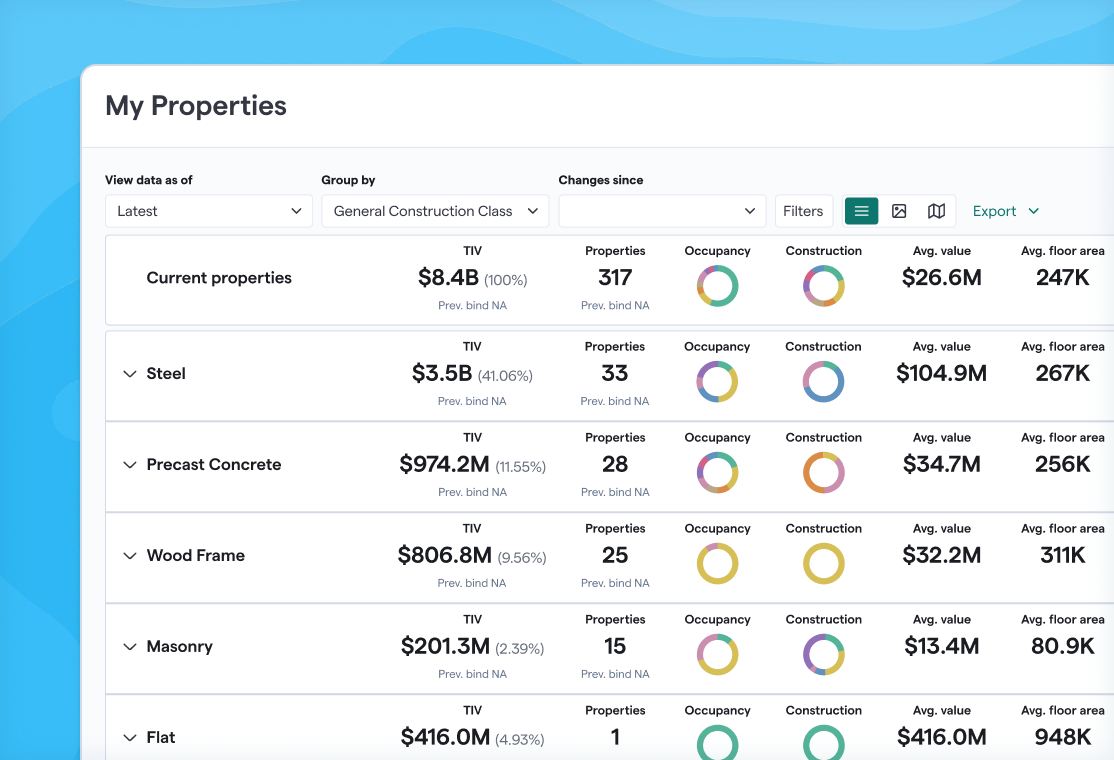
Comprehensive Schema
The schema represents data types developed and exhaustively validated across lots and a diverse range of exposure classes, from office and retail to industrial and logistics and healthcare to manufacturing — all meant to codify what matters for their unique businesses.
While specific, the schema remains agnostic and is not tied to any particular modeling formats.

AI / ML Transformations
The Archipelago Data Model employs machine learning-driven transformations, incorporating validation rules derived from known data and structural engineering patterns. For instance, Archipelago has the ability to automatically identify potential adjustments to a building's construction details based on the year it was built and its geographic location.
These transformative processes continually enhance their intelligence and precision as we handle more property schedules.
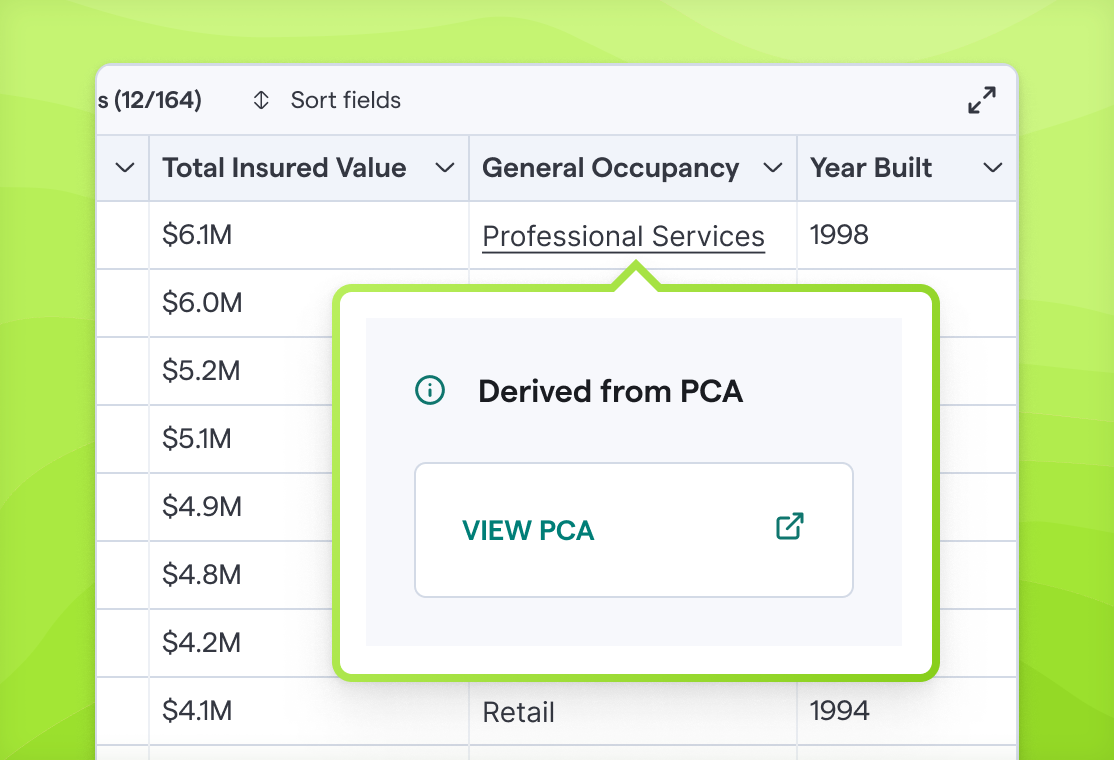
Document-Based Enrichment
Archipelago's enrichment layer employs machine learning tools first, followed by human-in-the-loop processes to extract validated information from source documents. These data points are then automatically linked to their original source documentation, creating trust in the data akin to virtual inspections.
"Archipelago brings the value of third-party expertise to enrich, augment and standardize data. Our ability to provide credible, validated data in a model-ready format differentiates our clients and us to the markets. "
.png?width=300&height=300&name=Martha%20Bane%20(Purple).png)
Martha Bane
Property Practice Leader at Arthur J. Gallagher
“Archipelago enabled us to increase control and consolidation of our data and feel confident in our risk decisions — including the option to buy $50M less in CA Earthquake with the same return period.”
.png?width=300&height=300&name=Deborah%20Ravetti%20(Lime%20Green).png)
Deborah Ravetti
Risk Manager at Shorenstein Properties LLC
SOV Manager
Simplify tedious data management
PreCheck
Quickly assess property data quality
Property Data Hub
Demonstrate superior data capabilities
Submission
Track engagement with markets